15億パラメーターの蒸留モデル、DeepSeek-R1-Distill-Qwen-1.5BをGoogle Colabで検証。
ハードウェアアクセラレータを変更する
画面右上の接続の右横の「▼」 -> 「ランタイムのタイプを変更」をクリック。
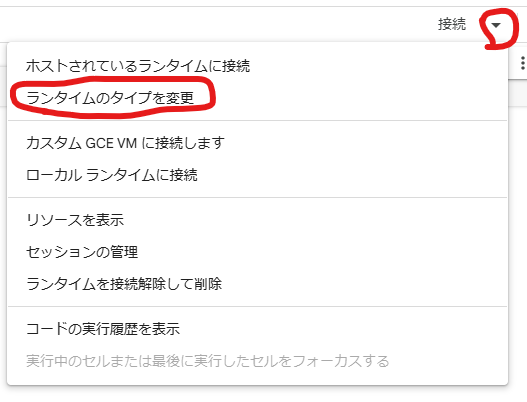
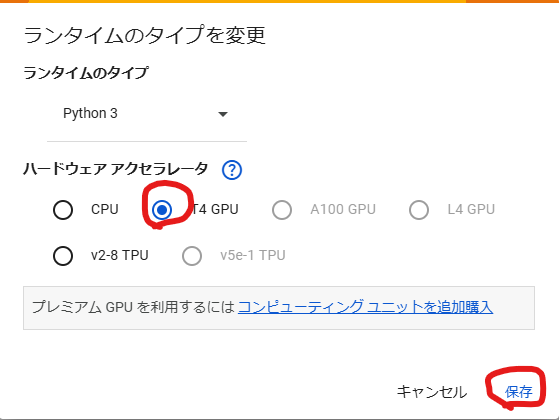
「T4 GPU」に変更して「保存」をクリック。
ソースコード
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Please tell me the highest mountain in Japan."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
pad_token_id=tokenizer.eos_token_id,
max_new_tokens=1024,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)検証結果
応答時間は50秒くらい。
日本語での質問はかなりトンチンカンな回答が返ってくる。かと言って英語で質問しても使えるレベルではないかな(笑)。
英語でシルクロードや万里の長城など中国のことを聞くと割とまともな回答が返ってきた。
しかし、1.5bのモデルでGPUメモリ15GBで動作するのはすごいと思う。